GraphQL was developed internally at Facebook by Nick Shrock, Lee Byron, and Dan Schafer in 2012, and it was released as an open-source project to the public in 2015. The list of companies using GraphQL is impressive, for example, Shopify, GitHub, Twitter, Pinterest, Stripe, and Photobox are all are using GraphQL and companies such as Amazon are creating GraphQL apps and content management tools supporting the move to GraphQL.
When I asked Christopher Taylor-Davies, Enterprise Architect at Photobox, why he thought that GraphQL was gaining so much momentum after being available for the past three years, he said “It's a relatively lightweight framework that doesn't demand that you do things in a certain way. With just a little bit of tweaking, you can make it talk to a broad range of backend services and provide a simple way for your clients to connect to diverse systems. It survived the scrutiny of early interest by delivering, and because it didn't break things, people kept using it.”
The following delves into what GraphQL is and the basics of how it works, its pros and cons, and what is likely to be the future for GraphQL.
What is GraphQL?
The “QL” in GraphQL stands for query language. However, GraphQL is actually a specification. Nick Shrock, one of the creators of GraphQL, points out that “GraphQL does not mandate a specific language backend, and it does not mandate a specific storage engine...It is all about a standardized type system and a standardized API...A GraphQL server exposes a single endpoint. That endpoint parses and executes a query, that query executes over a type system that’s defined in the application server.”
The “Graph” in GraphQL refers to the organized data on the application server in a graph structure. The following shows an example of book and author data organized in a graph. In GraphQL there is one endpoint that returns a data graph. Each object represents a node, and the edges between the objects represent the connections to the objects in the graph.
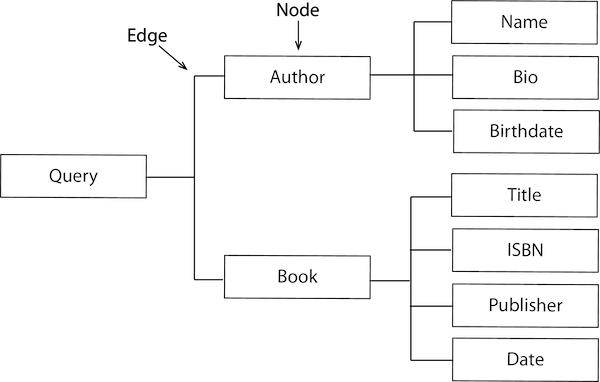
Book and author data in an application server data graph
The Basics of GraphQL
GraphQL has three main building blocks: the schema, queries, and resolvers. In addition to these building blocks, GraphQL includes an impressive introspection feature. The following sections explain each of these and examine how they work together.
The Grand Plan: The GraphQL Schema
GraphQL has a schema, so there is a type structure that describes the shape of your data. The schema defines an object type for each node. A GraphQL service defines a set of types which thoroughly describes the set of data you can query on that service. When queries are received, they are validated and executed against that schema. In other words, the schema is the data definition used for the request, and a type system defines all data that can be given in a query response. GraphQL defines some object types out of the box. For example, query type and scalar types, such as integer, string, and boolean. The API developer defines the rest of the objects using the GraphQL Schema Definition Language (SDL). The following is an example of a snippet of a schema that shows how each element has a type definition.
type Book {
id: ID
title: String
published: Date
author: Author
}
type Author {
id: ID
name: String
book: [Book]
}
The Ask: GraphQL Queries
A query is precisely that, a query or request from the server for specific data. The following is an example of a GraphQL query that asks for a book and author by its ID number.
type Query {
book(id: ID): Book
author(id: ID): Author
}
Using REST you would need to create multiple endpoints that you would have to write individual requests for, so you would need one request for book information and another request for author information. With REST, it is possible to code workarounds to parse data and only include the data you want, however, GraphQL gives you a standardized way to get all the information with a single query.
Suppose that you want to get additional info about an author and the books he or she has written. Using REST would require multiple requests or creating a custom workaround to get each book by the author, but with GraphQL it requires a single GraphQL query, as shown in the following example.
{
book(id: 100) {
title
isbn
date
author {
name
bio
books {
name
}
}
}
}
The beauty of this is that you can selectively get data without having to make multiple round trips to fetch the data.
Let’s say you are creating an app that needs lots of different kinds of data, in different contexts. Instead of formulating multiple queries, one for each context, GraphQL lets you use one query to give you all the data that you need.
Making It Happen: GraphQL Resolvers
A resolver is what is responsible for accessing your data. A resolver tells GraphQL how and where to fetch the data corresponding to a given field. For example, a resolver might be used to fetch the title of a book. REST APIs follow the CRUD (Create Read Update and Destroy) model that is used to operate on a resource. In GraphQL resolvers are defined on an individual object, so each data type in your data graph will be supported by a resolver.
Unlike REST, there is no mapping between functions implemented on the server and HTTP methods. So you are not required to use a GET request to fetch data, nor are you required to use a POST request to change or delete data.
Say, for example, you use an HTTP POST request to query the server for data; the API will start executing at the query root. The query goes through each field, executing a resolver for each field. The resolver sends the response back to the client, and the server’s response mirrors the client’s request. In other words, the resolver takes the name of the requested object as the key value and the “resolve value” becomes the returned value.
Looking Within: GraphQL’s Introspection System
GraphQL provides an “introspection system,” an inherent self-documenting feature that lets you use queries to return information about themselves. Introspection makes a GraphQL schema discoverable and machine-readable. Software that works with GraphQL queries doesn’t have to be permanently connected to work with any particular set of fields; it can ascertain the fields automatically. Introspection is a helpful feature built into the GraphQL API so that when you type a new field name, an IDE can automatically offer possible field names directly with autocomplete. Another feature of the introspection system is that you can use it to access documentation about the type system and create context-driven documentation.
The Benefits of GraphQL
The most significant benefit of GraphQL is that it allows for relational queries with one trip to the API. While a REST API requires loading from multiple URLs or coding workarounds, GraphQL presents a standardized API for queries that enable you to follow references between them. GraphQL APIs get all the data your app needs in a single request so that an app using GraphQL executes quickly even on slow connections. GraphQL’s introspection system is also a big plus for helping developers ensure that coding is correct and providing built-in documentation.
Since GraphQL is language and system agnostic, the market is bursting with support for GraphQL. There are several popular languages, server-side frameworks, client libraries, and services available for working with GraphQL. You implement the GraphQL API on the server-side, and there are some great GraphQL servers, such as Apollo, Express, and Prisma. On the client-side, Relay is Facebook’s open-source GraphQL client, and Apollo Client is an extremely popular community-driven client. Additionally, there are some fantastic GraphQL tools, such as GraphiQL (Note the “i” before QL), a first-class debugging tool that gives you hints and points out errors as you type. Another example is Gatsby’s GraphQL powered site generator that lets you build websites by pulling data from headless CMSs, such as Contentstack (a shameless plug), SaaS services, APIs, databases, and so on.
The Problems with GraphQL
GraphQL is not the panacea API. There are plenty of people on the web bashing GraphQL and letting you know about its shortcomings. Some of the things that are difficult with GraphQL include hiding data, versioning, representing state, and server caching issues. Third parties are already addressing some of these issues. For example, Apollo provides stack libraries for hiding data, Apollo Link State for handling state, and Apollo Cache-Control for GraphQL caching. Some issues are just treated differently by GraphQL. The GraphQL site states in its best practices docs that it “takes a strong opinion on avoiding versioning by providing the tools for the continuous evolution of a GraphQL schema.” GraphQL is also subject to the same vulnerabilities as any web application so that access control implementation is crucial.
The Future of GraphQL
GraphQL is a standardized API that reduces the amount of code to write, is less prone to errors, and provides built-in documentation. In most cases, building an app with GraphQL is the better choice than REST since it delivers a standard for one-trip relational queries, rather than multiple round-trip queries that not only slow down your app, but they also eat into your data plan. GraphQL’s single trip, standardized architecture is ultimately better, cheaper, and faster than the REST alternative. While it has its shortcomings, these issues are bound to be resolved over time. It is likely that GraphQL will continue to gain popularity over REST in the future as new developers begin by choosing GraphQL over REST as their starting point.